
Current, 2026
Wednesday, July 15
July
Luna’s projects are doing well. As a founder, the biggest unlock is seeing your product being used by real people and your business generating revenue. Lunr generating revenue is one of those big milestones for us, and with 0 external investment. It validates our solution and gives us the confidence to keep building. Here’s Lunr’s first revenue chart!
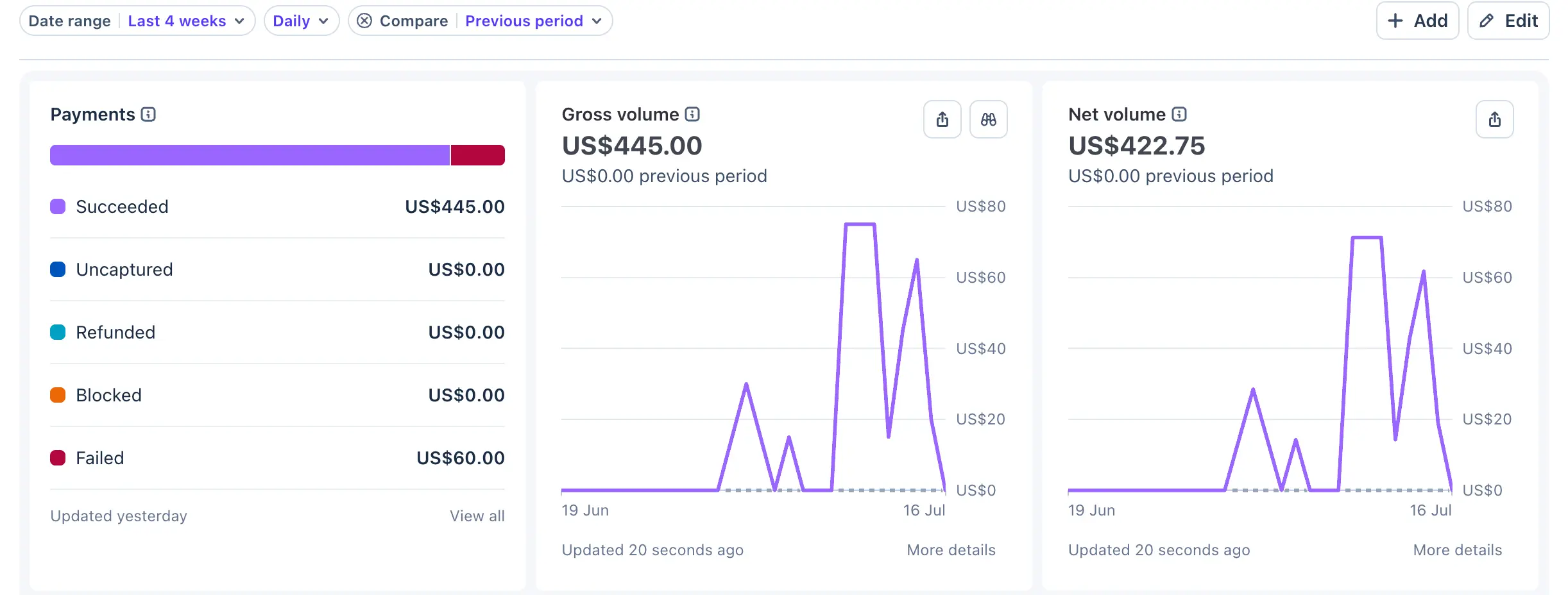
Excited for what’s next.
June
Back home, June is calmer. Fam is here and we are exploring the west coast now. The east coast tour was incredible. We rented an SUV and drove from New York to Niagara Falls, and the road trip was one of the best experiences of my life. Saw upstate New York, the beautiful landscapes, the little towns, the waterfalls. It was all picturesque. Driving around upstate NY was like being in a movie. The weather was perfect, the roads were empty, the trees were lush and green, the little towns were adorable, and sky transitioned from blue to yellow to orange, reddish, and then to purple as the sun set. It was truly and literally magical.
Back to grind mode now. Luna and Voicebit are doing well, and I am heads down on building. Busy rest of the year ahead.
May
An amazing launch to lunr! I’ve been working on Lunr for the past couple of months, and it’s finally live! Lunr is a matchmaking platform made for intentional dating. It matches you with one person at a time where you decide if you want to match/ continue the conversation or not. The goal is to create a more meaningful and intentional dating experience, where you can focus on one person at a time and get to know them better.




Luna is your chat-based AI twin, your wingman, where you talk to it and it prowls the city overnight to find the one by dawn. It may take a few matches for Luna to really learn you, but she’ll get it done. Think chatgpt, where you tell it what you like, dislike, what you want, and it finds you the best match.
May is extremely hectic, and has a lot of things in store — attending graduation ceremony, a trip to New York, launching a new venture, and more. My family is also visiting me in NY this month, and the second half of the month is going to be all about exploring NY with them.
April
One whole month of settling in. I’m starting to get the hang of things, beginning to feel more at home. In April, Luna Labs had an incredible growth spurt, did a lot of great work, and made the highest impact/ money till now. The city is beautiful, and the weather is amazing, but I am still getting used to it. Most days feel tiring, and a little overwhelming and anxious. SF is calmer, more laid back, naturally beautiful, and has a lot of techies. Still trying to find my groove here, but excited to explore what it has to offer.
March
March brings forth a few bittersweet changes. The sweet part: I am now the founding engineer at Voicebit, a voice-based AI food ordering system :). We are replacing the friction in food ordering by creating an end-to-end voice-based AI system that allows users to discover restaurants, explore menus, and place orders seamlessly.
With this, my journey at Authentic comes to an end. It has been an incredible ride and I’ll forever be grateful for getting to build this. The bitter part about all this is leaving New York.
New York (Technically, the bank of Hudson in Jersey City) has been my home for the past two years, and I have loved every. single. bit. of it. Growing up watching Friends and HIMYM, a life in NYC, living with a bunch of friends, was basically all I ever wanted.
The best thing about New York, at least for me, is the people. NY instantly makes you feel at home. The city is home to a huge diaspora of diverse immigrants. You get to meet a lot of people, and every third person speaks a different language and comes from a different corner of the world. It instills a sense of belonging and stability — “you aren’t alone; see, all these people have also left their own countries and are living here with you.” It just feels like it’s nobody’s home… and everybody’s home. The rent and taxes drive you nuts, but the food, culture, and life experiences more than make up for it.
NY had a ton of magic dust to sprinkle. Getting lost in the lives of people from around the world; walking with friends in the middle of the night; the ramen places always around the corner; the huge slices of pizza; the little deli shops with their sandwiches and energy drinks; the gelatos and cheesecakes; the halal carts and their shawarmas; the traffic and the jaywalking; watching the sunset from DUMBO; the feeling of never being alone because a million people are always walking with you; walking and exploring little nooks and corners with friends, talking about life; the little food festivals; the taco joints and their Indian-flavored tacos; watching the lives of people unfold in the subway are magical.
The weather, although horrible at times, was something I was getting used to. I am not that bothered by the cold, but the gloomy, cloudy weather in winter and spring are unbearable. I am a big-time sun-worshipper, and the beautiful falls and the sweltering summers are some of the most magical days of my life that I will miss dearly.

I still plan on (or at least will try to) visit New York every month. Can’t stay away for too long.
Ending this on a sweeter note: I am moving to San Francisco! Building and scaling a tech venture studio, SF is the best place to be. I have some experience here from last summer, when I was working at h011yw00d. Excited for what’s next — the unknown and the adventures are what make life worth living.
February
Reverse engineered the bluetooth signals and built this custom CLI app that monitors production state of our app and can change colors based on CI failures and sentry logs.
It’s been a busy start to the year. The weather in New York has been extremely cold in the past month. The last two weeks have been extremely busy and productive. I have been working on multiple projects at work, and have been heads down on building.
Running and scaling Luna has been good. Speaking to a couple of potential co-founders and trying out (gambling) a few ideas. The process is fun, but extremely exhausting. Will write about all of this in more detail.
In the current economy, where tech stocks are underperforming NASDAQ, I have no idea what to expect in the next few weeks. A couple of models later, I think everything I do and think will be obsolete. I’d have to hunt for new jobs. I might try out astrophysics, or philosophy, or maybe even consider farming. Claude and GPT will be taking over the world anytime now.
After the dust settles, I’d like to leave and explore the world for a bit. Spend some time vacationing somewhere warm.
January
Happy New Year! Kicking off 2026 with a renewed focus on personal growth and exploration. The new:
- Authentic is now live on both app stores. Excited to see how you guys engage with it! (iOS | Android)
- Tried snowboarding for the first time. Loved it. Planning to visit the mountains more often this year. Goal is to do a black diamond run in a year.
- Back to focusing on fitness. Set a goal to reach a certain body-fat percentage by mid-year.
- Engaged in a few exciting projects at work, including a new AI initiative plus a community platform. More details to come soon.
In other news, excited to launch Luna, my venture studio! Luna is one month old, already generating revenue, has multiple projects in the pipeline, and is setting up a venture of its own. Looking forward to sharing more updates soon.